И
Можно купить80 ₽ 800 ₽ −90%
Вы научитесь решать задачи классификации и кластеризации на примере реального соревнования Prudential с платформы Kaggle. В ходе обучения вы пройдете путь от первичного анализа данных до формирования финального предсказания, которое можно отправить на проверку.
Внутри разбираются:
Курс ориентирован на Python-аналитиков и специалистов по работе с большими данными, которые хотят освоить прикладные методы машинного обучения на практике.
 Можно купить
Можно купитьОтзывов пока нет. Будьте первым!
 Можно купить
Можно купить Можно купить
Можно купить Можно купить
Можно купить Можно купить
Можно купить Можно купить
Можно купить Можно купить
Можно купить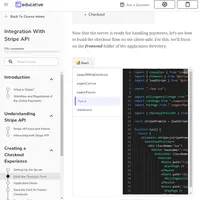 Предзаказ
Предзаказ Сбор взносов
Сбор взносов